
혜미의 개발 일지
[SQL] MSSQL 계층형 쿼리 CTE 본문
계층형쿼리란 재귀 쿼리랑도 같다.
재귀의 의미는 자기자신을 부르는 것이고,
MSSQL은 그걸 CTE 테이블이라고도 부른다.
[SQL] 계층형 쿼리 (ORACLE, MSSQL) #2
이전 글에서는 계층형 데이터에 대해 알아봤습니다. 동일 테이블 안에 상위, 하위 데이터가 포함된 데이터...
blog.naver.com
내가 구현한 cte 는 조인에서 코드값으로 줬었는데 중복이 아닌 값으로 조인하여 잘못나와서 고유값 seq를 조인하고 sort대신 seq로 정렬순 하였다. (사실 이 방법은 뭔가 틀린거 같은데.. 원하는 결과는 이렇다.)
WITH CODE_CTE (
SEQ
, CODE_CD
, CODE_NM
, UP_CODE_CD
, DEPTH
, LEVEL
, SORT
) AS (
SELECT
A.SEQ
, A.CODE_CD
, A.CODE_NM
, A.UP_CODE_CD
, 0 AS DEPTH
, 0 AS LEVEL
, CONVERT( VARCHAR(100), A.CODE_CD ) AS SORT
FROM table.DBO.CODE_MST_T A
WHERE ISNULL( A.UP_CODE_CD, '' ) = '' OR ISNULL( A.UP_CODE_CD, '' ) = '0'
UNION ALL
SELECT
B.SEQ
, B.CODE_CD
, B.CODE_NM
, B.UP_CODE_CD
, C.DEPTH + 1 AS DEPTH
, C.LEVEL + 1 AS LEVEL
, CONVERT( VARCHAR(100), C.SORT + ' < ' + RIGHT( '00' + CONVERT( VARCHAR(100), B.CODE_ORD ), 3 ) ) AS SORT
FROM table.DBO.CODE_MST_T B
INNER JOIN CODE_CTE C ON B.UP_CODE_CD = C.CODE_CD
WHERE ISNULL( B.UP_CODE_CD, '' ) != '' AND ISNULL( B.UP_CODE_CD, '' ) != '0'
AND B.UP_CODE_CD = C.CODE_CD
) SELECT
EA.SEQ
, EA.CODE_CD
, EA.CODE_NM
, EA.UP_CODE_CD
, EB.CODE_TYPE
, EB.CODE_ORD
, EB.USE_YN
, EB.REMARK
, ISNULL( CONVERT( VARCHAR(10), EB.CREATED_AT, 121 ),'') AS createdAt
, EB.CREATED_ID AS createdId
, ISNULL( CONVERT( VARCHAR(10), EB.UPDATED_AT, 121 ),'') AS updatedAt
, EB.UPDATED_ID AS updatedId
FROM CODE_CTE EA
INNER JOIN table.DBO.CODE_MST_T EB ON EB.SEQ = EA.SEQ
WHERE 1=1
]]>
<if test="searchKeyword != null and !searchKeyword.equals('')">
AND (
(
EB.CODE_CD LIKE ('%'+ #{searchKeyword} + '%')
OR EB.CODE_NM LIKE ('%'+ #{searchKeyword} + '%')
OR EB.REMARK LIKE ('%'+ #{searchKeyword} + '%')
)
OR EB.UP_CODE_CD IN (
SELECT SA.CODE_CD
FROM table.DBO.CODE_MST_T SA
WHERE 1=1
AND (
SA.CODE_CD LIKE ('%'+ #{searchKeyword} + '%')
OR SA.CODE_NM LIKE ('%'+ #{searchKeyword} + '%')
OR SA.REMARK LIKE ('%'+ #{searchKeyword} + '%')
)
)
)
ORDER BY EA.SEQ ASC , EA.SORT ASC, EA.UP_CODE_CD ASC
이와 같은 코드는 상위 코드내에 하위코드가 있는 것이고 비슷한 예제로 메뉴 같은게 있다. 내가 짠 코드 쿼리도 메뉴 쿼리를 참조하여 만들었었다.
계층형 쿼리의 개념에 대해여 잘 정리된 사이트를 참조하여 가져왔다.
계층형 질의와 셀프 조인
1. 계층형 질의
테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(Hierarchical Query)를 사용한다. 계층형 데이터란 동일 테이블에 계층적으로 상위와 하위 데이터가 포함된 데이터를 말한다. 예를 들어, 사원 테이블에서는 사원들 사이에 상위 사원(관리자)과 하위 사원 관계가 존재하고 조직 테이블에서는 조직들 사이에 상위 조직과 하위 조직 관계가 존재한다. 엔터티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. 순환관계 데이터 모델의 예로는 조직, 사원, 메뉴 등이 있다.

[그림 Ⅱ-2-6]은 사원에 대한 순환관계 데이터 모델을 표현한 것이다. (2)계층형 구조에서 A의 하위 사원은 B, C이고 B 밑에는 하위 사원이 없고 C의 하위 사원은 D, E가 있다. 계층형 구조를 데이터로 표현한 것이 (3)샘플 데이터이다. 계층형 데이터 조회는 DBMS 벤더와 버전에 따라 다른 방법으로 지원한다. 여기서는 Oracle과 SQL Server 기준으로 설명한다.
가. Oracle 계층형 질의
Oracle은 계층형 질의를 지원하기 위해서 [그림 Ⅱ-2-7]과 같은 계층형 질의 구문을 제공한다.

- START WITH절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉, 루트 데이터를 지정한다.(액세스) - CONNECT BY절은 다음에 전개될 자식 데이터를 지정하는 구문이다. 자식 데이터는 CONNECT BY절에 주어진 조건을 만족해야 한다.(조인) - PRIOR : CONNECT BY절에 사용되며, 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 자식 데이터에서 부모 데이터(자식 → 부모) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 부모 데이터에서 자식 데이터(부모 → 자식) 방향으로 전개하는 역방향 전개를 한다. - NOCYCLE : 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타난다면 이것을 가리켜 사이클(Cycle)이 형성되었다라고 말한다. 사이클이 발생한 데이터는 런타임 오류가 발생한다. 그렇지만 NOCYCLE를 추가하면 사이클이 발생한 이후의 데이터는 전개하지 않는다. - ORDER SIBLINGS BY : 형제 노드(동일 LEVEL) 사이에서 정렬을 수행한다. - WHERE : 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출한다.(필터링)
Oracle은 계층형 질의를 사용할 때 다음과 같은 가상 칼럼(Pseudo Column)을 제공한다.

다음은 [그림 Ⅱ-2-6]의 (3)샘플 데이터를 계층형 질의 구문을 이용해서 조회한 것이다. 여기서는 결과 데이터를 들여쓰기 하기 위해서 LPAD 함수를 사용하였다.
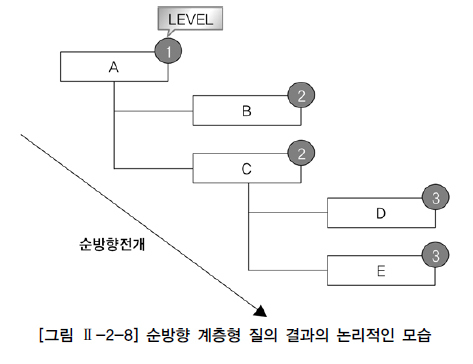
A는 루트 데이터이기 때문에 레벨이 1이다. A의 하위 데이터인 B, C는 레벨이 2이다. 그리고 C의 하위 데이터인 D, E는 레벨이 3이다. 리프 데이터는 B, D, E이다. 관리자 → 사원 방향을 전개이기 때문에 순방향 전개이다. [그림 Ⅱ-2-8]은 계층형 질의에 대한 논리적인 실행 모습이다.
다음 예제는 사원 'D'로부터 자신의 상위관리자를 찾는 역방향 전개의 예이다.
본 예제는 역방향 전개이기 때문에 하위 데이터에서 상위 데이터로 전개된다. 결과를 보면 내용을 제외하고 표시 형태는 순방향 전개와 동일하다. D는 루트 데이터이기 때문에 레벨이 1이다. D의 상위 데이터인 C는 레벨이 2이다. 그리고 C의 상위 데이터인 A는 레벨이 3이다. 리프 데이터는 A이다. 루트 및 레벨은 전개되는 방향에 따라 반대가 됨을 알 수 있다. [그림 Ⅱ-2-9]는 역방향 전개에 대한 계층형 질의에 대한 논리적인 실행 모습이다.

Orcle은 계층형 질의를 사용할 때 사용자 편의성을 제공하기 위해서 [표 Ⅱ-2-3]과 같은 함수를 제공한다

SYS_CONNECT_BY_PATH, CONNECT_BY_ROOT를 사용한 예는 다음과 같다.
START WITH를 통해 추출된 루트 데이터가 1건 이기 때문에 루트사원은 모두 A이다. 경로는 루트로부터 현재 데이터까지의 경로를 표시한다. 예를 들어, D의 경로는 A → C → D 이다.
나. SQL Server 계층형 질의
SQL Server 2000 버전까지는 계층형 질의를 작성 계층적 구조를 가진 데이터는 저장 프로시저를 재귀 호출하거나 While 루프 문에서 임시 테이블을 사용하는 등 (순수한 쿼리가 아닌) 프로그램 방식으로 전개해야만 했다. 그러나 SQL Server 2005 버전부터는 하나의 질의로 원하는 결과를 얻을 수 있게 되었다. 먼저, Northwind 데이터베이스에 접속하여 Employees 테이블의 데이터를 조회해 보자.
총 9개 로우가 있는데, ReportsTo 칼럼이 상위 사원에 해당하며 EmployeeID 칼럼과 재귀적 관계를 맺고 있다. EmployeeID가 2인 Fuller 사원을 살펴보면, ReportsTo 칼럼 값이 NULL이므로 계층 구조의 최상위에 있음을 알 수 있다. CTE(Common Table Expression)를 재귀 호출함으로써 Employees 데이터의 최상위부터 시작해 하위 방향으로 계층 구조를 전개하도록 작성한 쿼리와 결과는 다음과 같다.
WITH 절의 CTE 쿼리를 보면, UNION ALL 연산자로 쿼리 두 개를 결합했다. 둘 중 위에 있는 쿼리를 ‘앵커 멤버’(Anchor Member)라고 하고, 아래에 있는 쿼리를 ‘재귀 멤버’(Recursive Member)라고 한다. 아래는 재귀적 쿼리의 처리 과정이다.
1. CTE 식을 앵커 멤버와 재귀 멤버로 분할한다. 2. 앵커 멤버를 실행하여 첫 번째 호출 또는 기본 결과 집합(T0)을 만든다. 3. Ti는 입력으로 사용하고 Ti+1은 출력으로 사용하여 재귀 멤버를 실행한다. 4. 빈 집합이 반환될 때까지 3단계를 반복한다. 5. 결과 집합을 반환한다. 이것은 T0에서 Tn까지의 UNION ALL이다.
정리하자면 다음과 같다. 먼저, 앵커 멤버가 시작점이자 Outer 집합이 되어 Inner 집합인 재귀 멤버와 조인을 시작한다. 이어서, 앞서 조인한 결과가 다시 Outer 집합이 되어 재귀 멤버와 조인을 반복하다가 조인 결과가 비어 있으면 즉, 더 조인할 수 없으면 지금까지 만들어진 결과 집합을 모두 합하여 리턴한다. [그림 Ⅱ-2-10]에 있는 조직도를 쿼리로 출력했을 때, 대부분 사용자는 아래와 같은 결과를 기대할 것이다.(보기 편하도록 각 로우 앞쪽에 자신의 레벨만큼 빈칸을 삽입했다.)

아래에 t_emp 데이터의 최상위부터 시작해 하위 방향으로 계층 구조를 전개하도록 작성한 쿼리와 그 결과이다.
보다시피, 계층 구조를 단순히 하위 방향으로 전개했을 뿐 [그림 Ⅱ-2-10]에 있는 조직도와는 많이 다른 모습이다. 앞서 보았듯이, CTE 재귀 호출로 만들어낸 계층 구조는 실제와 다른 모습으로 출력된다. 따라서 조직도와 같은 모습으로 출력하려면 order by 절을 추가해 원하는 순서대로 결과를 정렬해야 한다. 실제 조직도와 같은 모습의 결과를 출력하도록, CTE에 Sort라는 정렬용 칼럼을 추가하고 쿼리 마지막에 order by 조건을 추가해보자.(단, 앵커 멤버와 재귀 멤버 양쪽에서 convert 함수 등으로 데이터 형식을 일치시켜야 한다.)
CTE 안에서 Sort 칼럼에 사번(=EmployeeID)을 재귀적으로 더해 나가면 정렬 기준으로 삼을 수 있는 값이 만들어진다. 아래는 Sort 칼럼으로 정렬하여 출력한 결과인데, [그림 Ⅱ-2-10]에 있는 조직도의 모습과 일치한다.
가상의 Sort 칼럼을 추가해 정렬하는 게 아쉽기는 하지만, SQL Server에서 계층 구조를 실제 모습대로 출력하려면 현재(2005, 2008 버전 기준)로서는 감수해야 할 수밖에 없다.
2. 셀프 조인
셀프 조인(Self Join)이란 동일 테이블 사이의 조인을 말한다. 따라서 FROM 절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조인을 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해 반드시 테이블 별칭(Alias)를 사용해야 한다. 그리고 칼럼에도 모두 테이블 별칭을 사용해서 어느 테이블의 칼럼인지 식별해줘야 한다. 이외 사항은 조인과 동일하다.
셀프 조인에 대한 기본적인 사용법은 다음과 같다
계층형 질의에서 살펴보았던 사원이라는 테이블 속에는 사원과 관리자가 모두 하나의 사원이라는 개념으로 동일시하여 같이 입력되어 있다. 이것을 이용해서 다음 문제를 셀프 조인으로 해결해 보면 다음과 같다. “자신과 상위, 차상위 관리자를 같은 줄에 표시하라.” 이 문제를 해결하기 위해서는 FROM 절에 사원 테이블을 두 번 사용해야 한다.

셀프 조인은 동일한 테이블(사원)이지만 [그림 Ⅱ-2-11]과 같이 개념적으로는 두 개의 서로 다른 테이블(사원, 관리자)을 사용하는 것과 동일하다. 동일 테이블을 다른 테이블인 것처럼 처리하기 위해 테이블 별칭을 사용한다. 여기서는 E1(사원), E2(관리자) 테이블 별칭을 사용하였다. 차상위 관리자를 구하기 위해서 E1.관리자 = E2.사원 조인 조건을 사용한다. 셀프 조인을 이용한 SQL문은 다음과 같다.
자신과 자신의 직속 관리자는 동일한 행에서 데이터를 구할 수 있으나 차상위 관리자는 바로 구할 수 없다. 차상위 관리자를 구하기 위해서는 자신의 직속 관리자를 기준으로 사원 테이블과 한번 더 조인(셀프 조인)을 수행해야 한다. 결과 표시를 위해 SELECT절에 2개의 ‘관리자’ 칼럼을 사용되었다. 한 명은 자신의 직속 관리자(E1.관리자)이고 다른 한 명은 자신의 차상위 관리자(E2.관리자)이다. 결과를 보면, B와 C의 관리자는 A이고 차상위 관리자는 없다. D와 E의 관리자는 C이고 차상위 관리자는 A이다. 결과에서 A에 대한 정보는 누락되었다. 내부 조인(Inner Join)을 사용할 경우 자신의 관리자가 존재하지 않는 경우에는 관리자(E2) 테이블에서 조인할 대상이 존재하지 않기 때문에 해당 데이터는 결과에서 누락된다. 이를 방지하기 위해서는 아우터 조인을 사용해야 한다. 다음은 아우터 조인을 사용한 예이다.
아우터 조인을 사용해서 관리자가 존재하지 않는 데이터까지 모두 결과에 표시되었다.
참조 : 데이터 온에어
'DB > MSSQL' 카테고리의 다른 글
| [MSSQL] 월별, 일별, 주별, 년도별 통계 (0) | 2022.06.03 |
|---|---|
| [SQL] MSSQL WITH(NOLOCK) (0) | 2022.03.24 |